We are relatively familiar with Stallman's views on software freedom. These views are deeply based on the idea that we can enumerate rights which should be respected. However sometimes enumeration of rights gets in the way of actually having freedom, because of the assumption that anything beyond those rights are not rights at all. The idea of four freedoms essentially encourages a lawyer's view of software freedom where anything outside can be restricted in order to achieve the appearance of freedom.
This post provides a Distributist view of software freedom. It functions in part as an introduction to Distributist economic and political theory for open source software professionals and an introduction to open source software for Distributists. The approach will be shown to be very different than Stallman's or other groups but it also shows in greater detail why software freedom is important in a more general way than Stallman's enumerated rights approach shows.
It's worth noting off the bat that Distributism arose as a critique both of Capitalism and Communism and represents something with some of the ideals of both sides, but altogether different in character than either. It's my thesis that open source makes most sense when looked at through a distributist approach instead a liberal rights approach.
Economic Activity, Means of Production, and Ownership
Capitalist, Marxist, and Distributist economic theory is fundamentally based on the recognition of means of production and its place in regulating economic activity.
We humans no longer live, anywhere in the world, in unimproved conditions (say in trees without tools, clothing, or the like). For us to live we must improve our environment and make it more conducive to human activity. Production of goods and delivery of services, however, requires a few specifics: land, tools, labor, and capital. Without land, a business has nowhere to work. Without tools, there is nothing that can be done. Without labor there is nobody to do the work, and without capital there is no way to pay the costs to get started.
The means of production constitute two parts of this equation, namely land (facilities) and tools used to produce goods and deliver services. Labor and capital represent two other inputs but they are different in kind. Capital is expended flexibly, and labor is human input by the actual workers. Under a system of slavery, slaves might be included but otherwise, free workers are different in that they are not owned.
The term ownership is however somewhat problematic. Ownership itself is socially constructed, and can take different forms in different ways. The simplest, perhaps even most satisfying, definition of ownership is simply
the right to utilize, and direct utilization of, an item, particularly in production of economic goods or services. This definition largely follows that of Hilaire Belloc's
The Servile State which is one of the fundamental works of Distributist economic and historical theory.
Distributism, Capitalism, and Marxist Communism can be differentiated though as to who owns, in the sense of the right to utilize or direct utilization of the means of production. These represent fundamentally different approaches to trying to manage economic problems of a society (other approaches exist as well).
Capitalism, Communism, and Distributism as Economic Orders
For this discussion it is important to define these terms clearly and their relationship, so that the scope and type of the Distributist critique of Capitalism and Communism are understood. This is also a key to understanding the economic benefits of open source software. It is also worth noting that "perfect" examples of Capitalism, Communism, and Distributism are hard to find, so to some extent one has to ask what aspects of these three systems one finds in any given economic order. In fact one may find aspects of all three in the US today despite the fact that the US is one of the most clearly Capitalist economies around today.
Capitalism is a system where, in a class-based society, the class with capital buys land and tools, and hires labor to start businesses. Capitalism thus means "ownership by financier." Capitalism is fundamentally prone to market failures through mechanisms like overproduction, and workers are largely powerless because they have few options other than working for financier-owned businesses. As Adam Smith noted, wages and salaries are determined less by supply and demand and more by individual bargaining power, so the less empowered a worker is, the less the worker will earn.
Marxist Communism seeks to solve the problems of Capitalism by taking the means of production from the financiers and vesting those in the state as the representative of the worker. Of course the problems of Capitalism are caused by too few people having too much control, so further concentrating power in fewer hands will not solve the problem. Further, while financiers may have a primary goal of making money, government officials have complex goals and so the power that comes with control over economic production (which amounts to control over life itself) inevitably leads to great and terrible dictatorships.
Distributism looks back to the progression of the economy of the Middle Ages towards an economy where most people were effectively self-employed and thus seeks to undo the centralization of power that occurs under Capitalism by vesting ownership in the means of production with individual workers, not the state as an intermediary. An economy dominated by the self-employed would be a Distributist economy.
The Distributist critique of Capitalism at the beginning tracks the Marxist critique of Capitalism. Capitalism is seen to create problems for workers who are disadvantaged by wealthy business owners, but the mechanism of that disempowerment is different, and so here they begin to diverge. In essence because workers are denied the opportunity to participate in the economy as free agents, they are dependent on their employers for basic subsistence. This leads workers to demand better conditions which leads to class warfare. This threatens the liberal capitalist order, and results in some socialization of some things that the wealthy business owners are willing to give up for promises of greater gains in the future.
Unlike Marxists, Distributists usually assume that the wealthy classes, by virtue of their economic control, will usually win class warfare and this is well attested historically. Therefore Distributism seeks to avoid rather than stoke this warfare. The goal is to gently cultivate businesses and individuals where labor and capital are not separate and therefore not in conflict. A handyman who owns his own tools and pays for the start-up expenses of going into business is thus a job creator in a way in which venture capital firms are not. There is nothing more empowering to a worker than the ability to quit and easily start a business, so a porous border between formal employment and self-employment is believed to increase wages.
Software Ownership, EULA's and Open Source
Typically software is not sold but licensed. The licensee (end user) receives certain rights to utilize the software for certain purposes decided by the licensor. For this reason, if we define ownership as the right to utilize, particularly for economic production, software comes with a wide range of degrees of ownership.
Some software, for example, is free for non-commercial use. This offers a very limited degree of ownership (regarding economic production) unless often significant fees are paid. Other software comes with seemingly arbitrary limits which are specifically designed to provide upselling opportunities to the vendor either regarding software or license rights.
For example, in the past certain versions of Windows have included terms in their End User License Agreement specifying that web servers may not be run on the systems. The whole purpose is to ensure that people who want to run Apache on their systems must buy versions that also come with IIS.
Similarly client access licenses are typically used as a general upselling opportunity, so that larger users must pay more.
Of course one is only entitled to use what one pays for and therefore businesses using commercial off the shelf software often must spend time and energy ensuring they are compliant with all the various terms on every piece of software license.
Open source is different in that it provides very few limits on utilization at all, and some software (such as under the MIT license) provide few limitations on utilization at all.
In general open source software licenses allow unlimited utilization within a business. They provide varying degrees of restriction regarding utilization in products that incorporate the software, particularly in how much ownership can be asserted over the software once it is distributed to a customer.
Open Source Development Communities vs Dual-Licensing Companies
There are two predominant approaches to the development and distribution of open source software. The first is that of dual-licensing by a single company which holds the copyright and sells proprietary licenses in addition to an open source offering, often one which has fewer features. The second is the multi-vendor model where several companies come together to jointly offer an open source offering. The companies may or may not have their own proprietary offerings as well.
The big difference between these two models is in who has what degree of control over what people and businesses do with the software. In the first model, the company has the incentive to provide the software under a license with as many restrictions on utilization as possible. In the second, no one company has that power, and thus the incentive is to provide the software under fewer restrictions.
These differences largely show the Distributist position to be correct, that distribution of control means that the vendors have less control and that the workers and consumers have more. In essence programs developed and owned by communities are less restricted and more open than those which are developed and owned by single companies (owned meaning
having the right to tell you what you can or cannot do with the software).
The typical copyleft critique of BSD- and MIT-licensed software is that it gives too much freedom, to the point where it is not possible to enforce downstream software freedom. I think to some extent this is both incorrect and it misses the point. It is true that many permissively licensed projects have seen proprietary spinoffs which no longer contribute code back, but in the long view, these rarely outlive a project with significant vitality.
For example Solaris began as a proprietary spinoff of UC BSD. Other UC spinoffs, such as FreeBSD is still being actively developed but mostly under the same license approved by University of California. The only development on Solaris I am aware of is on an open source fork of OpenSolaris. Illustra was an early proprietary spinoff of
PostgreSQL. It was purchased and some code incorporated into Informix but otherwise died. Mammoth PostgreSQL is now alive only as an open sourced set of patches. We can expect that other forks in coming decades which have broken themselves off from community development will be unable to compete long run. History is littered with failed proprietary forks of BSD-licensed software.....
The community, however, continues.
The obvious counter-example is NCSA Mosaic, but it isn't clear that any proprietary forks of the browser survived either, and Mosaic was originally developed by a single entity. Thus this exception largely proves the rule.
The community endures. Companies come and go.
From this perspective corporations are actually not that powerful compared to the flexible network of developers building open source software. These networks in the case of many pieces of important software infrastructure, have proven remarkably robust:
- BSD began in 1977, and while the University of California Berkeley is no longer the one that manages development, several forks exist today (OpenBSD, FreeBSD, NetBSD, etc).
- PostgreSQL began in 1985 at UC Berkeley and like BSD escaped into the wild. It is one of the most successful open source database engines around.
- Apache Web Server was released first in 1995.
- The Linux Kernel was begun in ernest in 1991.
- TeX was initially released in 1978
- LaTeX was initially released in 1982
In comparison commercialization ventures of these areas have tended to be much shorter lived and many technologies that seemed like they were here to stay have disappeared or are dying (Flash being an example that comes to mind).
Thoughts on MIT, BSD, GPL, and AGPL Licenses
Careful observers will note I listed the licenses in order from the most permissive to the most restrictive.
Looking at open source from the eyes of a Distributist theory of economic production and ownership, the MIT, BSD, GPL, and AGPL licenses are differentiated regarding the specifics of the right to utilize that is passed downstream. Of these, the BSD license family provides, IMO, the best balance between the interests of market participants. Sublicensing is not allowed, but all other utilization is.
The permissive licenses are fundamentally more Distributist than the copyleft licenses are, and the copyleft licenses are more Capitalist than the permissive licenses are. With a copyleft license there are important rights retained for further licensing, so one can essentially require additional fees be paid upstream for certain uses. Much of my discussion here is drawn from
Larry Rosen's book on the subject.
The MIT license largely only requires attribution. One is allowed to do pretty much anything else with the software. This includes, notably, to sublicense it, in other words to sell part of one's rights received under the license to downstream parties. In other words, I can take MIT Kerberos, rename it to GuardDog Authentication Services (totally hypothetical name and any resemblance to a real product is purely coincidental), and sell it without making any modifications to the code at all. I can also incorporate the software with my products, and license the code with restrictions not present in the MIT license. In essence the MIT license differs from public domain only in that it requires attribution.
The BSD license is significantly more restrictive than the MIT license, in that the license does not mention sublicensing. I can take PostgreSQL, add important changes, and license the new product with restrictions not present in the original license. However, I cannot do this unless I add significant, copyright-worthy changes. The restrictions I add affect changes I make and the work as a whole, not the code I did not modify, and this is a significant difference from MIT-licensed code. While there are exceptions, the vast majority of IP lawyers I have discussed the interpretation of these licenses with concur with this interpretation.
The permissive licenses above have the advantage in that they pass downstream the right of those who do further development to fully own their work to the extent that society allows (through copyright law and the like). The copyleft licenses are different in that they pass only limited rights to utilize downstream to further developers.
In the description below I am going to avoid directly addressing hot topics like whether linking has anything to do with derivation. These arguments however further serve to limit the right to utilize the software by providing gray controversial zones of use and so I will note them. The copyleft licenses are efforts to enshrine and protect Stallman's 4 freedoms (the right to run the software, the right to study the software, the right to copy the software, the right to modify the software). This is obviously an intentional reference to the rhetorical framework of Roosevelt's New Deal, and it highlights what I think it the flaw in the copyleft approach.
Roosevelt's New Deal was sold to the public as a way out of the Great Depression and a way to help the poor who were suffering from the economic downturn. However the New Deal included programs intended to centralize industries (some of which were struck down by the Supreme Court prior to the court packing threat), and programs which supplanted organic, family-centric safety nets with impersonal institutions. In essence the New Deal was corporatist and paved the way for the neoliberalism which has ruled the West in recent decades. The same basic problems occur within the FSF's approach, which results in the GPL and AGPL are particularly popular with corporations wanting to reduce open source software to shareware. Note that regarding institutional control, the FSF advocates giving them (the FSF) control over future licensing changes to the software via an "or at your option any later version" clause in the licensing. For those of us trying to break up the corporate control over software, however, the New Deal is the wrong model. Trust-busting and common goods are the right model.
This is not to say that distributist approaches cannot use the GPL for their software. It is just to say that the BSD license is probably better in such areas. The fundamental difference is whether one is to see the primary method of preventing abuse being centralized regulation (via the FSF in the form of new versions of the GPL family of licenses) or decentralized downstream control (via multi-vendor communities). While these are not mutually exclusive, I don't think it is possible to both equally rely on centralization and decentralization at the same time. One has to choose one as primary. If you choose centralization, you have to pretty much follow the GNU model of requiring copyright assignments, etc. If you choose decentralization and not require copyright assignments, you have to admit that this dilutes the protections of the GPL, moving it more towards the BSD-family of licenses (because it is harder to prove copyright infringement when you have to prove ownership of code you created first).
The GNU GPL family of licenses places significant burdens on the right to utilize the software to produce new goods incorporating the software. This is due to the so-called viral nature of the license. One cannot close off the software and refuse to give downstream authors the same rights. However on top of that there are controversies around where this starts and stops which make this restriction remarkably broader than it might seem on the surface. The first is whether, as a copyright matter, you need permission to link to a library and utilize that library's code. This affects whether, in the GPL v2, a proprietary licensed library connected to a GPL'd application (or vice versa!) is mere aggregation or a derivative work under the full control of the GPL. This issue has never been resolved in court anywhere in the world to my knowledge and so people avoid doing this.
The GPL v3 is a very long, complex, legal contract which attempts to address the above issue among others (and it places further restrictions on goods produced regarding cryptographic signatures and the like). On the whole the license creates more problems than it solves. For example, everyone I have talked to agrees that the GPL v3 license and the BSD family of licenses (assuming no obnoxious advertising clauses) are compatible, but the view particularly of the FSF on what these licenses require is very different from what most lawyers I have talked to from the Software Freedom Law Center and independent IP lawyers have said. The question boils down to what section 7, Additional Terms, requires of other licenses, and whether (or, more properly, how) the BSD license can be construed to be compatible with that.
The mainstream view is that the licenses were intended to be compatible and so the GPL should be read to be compatible with the BSD license. This means that, since the BSD license does not mention sublicensing, the additional downstream permissions granted by the copyright holder take effect no matter what, and the 7(b) reasonable legal notices section should be read broadly enough to allow additional non-removable permissions granted by the copyright holder of certain contributions, provided the permissions only govern those contributions specifically. It is worth noting that the Software Freedom Law Center has dedicated significant resources towards publishing viewpoints explaining this specific position.
Another view I have heard (from Eben Moglen shortly after the GPL v3 was finalized, but to be honest I don't know if his view has changed) is to read the BSD license as allowing sublicensing and read the GPL as requiring a right to sublicense, and then read removal of permissions not as a sublicense per se but just as a notice that the code cannot be safely treated as BSD-licensed. But if this is the case and the BSD license does not grant that right, then it raises significant legal issues. As a software developer I don't feel like I can accept this interpretation of both licenses safely.
These controversies and others conspire to create a situation where there exists significant uncertainty about how one can safely utilize the software in the creation of new products. In general, one cannot go far wrong by following community norms, which treats the BSD license as compatible and linking to proprietary software and libraries as problematic, but these could be destabilized in the future with litigation and so it is a significant concern.
Of the copyleft licenses, the Affero GPL or AGPL stands alone for placing signficant restrictions on the utilization of software to deliver services. Of the licenses discussed, it is the one which is plainly incompatible with a Distributist approach to economic ownership. The AGPL requires that modifications to the software are available to the user of the software, when that user is interactively using the software as a service.
The AGPL is specifically intended to close the so-called SaaS loophole, but it is the wrong solution to the wrong problem. From a customer's perspective the primary concern with SaaS is not functionality but data ownership. If I take a piece of software and modify it, I can assume users can hire someone to re-implement the modifications easily enough, but if they don't have access to their raw data, they are stuck with me. This sort of lock-in is the real problem with SaaS from a competitive perspective but it cannot be reasonably addressed through software licenses while maintaining a commitment to distributed ownership and development, and freedom to utilize.
Conclusions
Free and open source software today is split between two models. The first, what we might call the Capitalist model of products like MySQL, which presuppose a single commercial entity holding total copyright ownership over the software. The second is the Distributist model where ownership and right to utilize is distributed. PostgreSQL is a good example as is FreeBSD. The second model is not incompatible with capitalist entities participating but they don't control the right to utilize the software in the same way. Similarly the Capitalist model can't stop Distributist off-shoots (see MariaDB and
LedgerSMB) and those offshoots are usually forced into a Distributist model because the founders cannot assert copyright control sufficient to engage in dual licensing.
In general, the Distributist understanding of property and business ownership provides a very different look at free and open source software, and why these are important even for non-programmers. These programs also provide a very good look at a Distributist economic order and how it can function in a Capitalist society's knowledge economy.
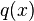 be a property provable about objects
be a property provable about objects  of type
of type  . Then
. Then 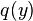 should be provable for objects
should be provable for objects  of type
of type  where
where