We use currently a stored procedure API divided into an upper and lower half, The upper half generates an API call for the lower half, which can be called independently when finer control is needed.
The Bottom Half
The bottom half of this mechanism is the stored procedure call API. The Perl API uses the following syntax:
@results = call_procedure( procname => $procname, args => $args );
@results is an array of hash references each of which represents a row returned. $procname is naturally the name of the procedure, and $args is an array reference of scalar argument values.
For example if I want to call a function named company__get which takes a single argument of $id, I might:
($company) = call_procedure(
procname => 'company__get', args => [$id]
);
This function then generates a query from the arguments of:
SELECT * FROM company__get(?);
And runs it, parameterized, with $id as the argument.
The full source code for the function in Perl is:
sub call_procedure {
my $self = shift @_;
my %args = @_;
my $procname = $args{procname};
my $schema = $args{schema};
my @call_args;
my $dbh = $LedgerSMB::App_State::DBH;
if (!$dbh){
$dbh = $self->{dbh};
}
@call_args = @{ $args{args} } if defined $args{args};
my $order_by = $args{order_by};
my $query_rc;
my $argstr = "";
my @results;
if (!defined $procname){
$self->error('Undefined function in call_procedure.');
}
$procname = $dbh->quote_identifier($procname);
# Add the test for whether the schema is something useful.
$logger->trace("\$procname=$procname");
$schema = $schema || $LedgerSMB::Sysconfig::db_namespace;
$schema = $dbh->quote_identifier($schema);
for ( 1 .. scalar @call_args ) {
$argstr .= "?, ";
}
$argstr =~ s/\, $//;
my $query = "SELECT * FROM $schema.$procname()";
if ($order_by){
$query .= " ORDER BY $order_by";
}
$query =~ s/\(\)/($argstr)/;
my $sth = $dbh->prepare($query);
my $place = 1;
# API Change here to support byteas:
# If the argument is a hashref, allow it to define it's SQL type
# for example PG_BYTEA, and use that to bind. The API supports the old
# syntax (array of scalars and arrayrefs) but extends this so that hashrefs
# now have special meaning. I expect this to be somewhat recursive in the
# future if hashrefs to complex types are added, but we will have to put
# that off for another day. --CT
foreach my $carg (@call_args){
if (ref($carg) eq 'HASH'){
$sth->bind_param($place, $carg->{value},
{ pg_type => $carg->{type} });
} else {
$sth->bind_param($place, $carg);
}
++$place;
}
$query_rc = $sth->execute();
if (!$query_rc){
if ($args{continue_on_error} and # only for plpgsql exceptions
($dbh->state =~ /^P/)){
$@ = $dbh->errstr;
} else {
$self->dberror($dbh->errstr . ": " . $query);
}
}
my @types = @{$sth->{TYPE}};
my @names = @{$sth->{NAME_lc}};
while ( my $ref = $sth->fetchrow_hashref('NAME_lc') ) {
for (0 .. $#names){
# numeric float4/real
if ($types[$_] == 3 or $types[$_] == 2) {
$ref->{$names[$_]} = Math::BigFloat->new($ref->{$names[$_]});
}
}
push @results, $ref;
}
return @results;
}
In addition to the portions described above, this function also does some basic error handling, delegating to another function which logs full errors and hides some errors (particularly security-sensitive ones) behind more generic user-facing error messages.
There is a modest amount more to the logic in terms of type handling and the like, but that's roughly it for the main logic.
Future Enhancements for the Bottom Half
In the future I would like to add a number of features including window definitions and window function aggregates which can be tacked on to a function's output. I would in essence like to be able to go from a maximum complexity of something like:
SELECT * FROM my_func(?) order by foo;
to
SELECT *, sum(amount)
over (partition by reference order by entry_id)
AS running_balance
FROM gl_report(?, ?, ?) order by transdate;
This sort of thing would make reporting functions a lot more flexible.
The Top Half
The top half serves as a general service with regard to the location of the stored procedure. The function is located in the DBObject module, and is called "exec_method." This function provides service location capabilities, provided that function names are unique (this may change in future generations as we experiment with other representations and interfaces).
The top half currently uses an object-property to argument mapping approach or an enumerated argument approach exclusively. There is no ability to mix these, which is a current shortcoming. The current code allows for an enumerated argument approach which I almost never use since it is relatively brittle.
Additionally the ordering API in the Perl code is really suboptimal and needs to be redone in future versions.
The Perl code is:
sub exec_method {
my $self = shift @_;
my %args = (ref($_[0]) eq 'HASH')? %{$_[0]}: @_;
my $funcname = $args{funcname};
my $schema = $args{schema} || $LedgerSMB::Sysconfig::db_namespace;
$logger->debug("exec_method: \$funcname = $funcname");
my @in_args;
@in_args = @{ $args{args} } if $args{args};
my @call_args;
my $query = "
SELECT proname, pronargs, proargnames FROM pg_proc
WHERE proname = ?
AND pronamespace =
coalesce((SELECT oid FROM pg_namespace WHERE nspname = ?),
pronamespace)
";
my $sth = $self->{dbh}->prepare(
$query
);
my $ref;
$ref = $sth->fetchrow_hashref('NAME_lc');
my $pargs = $ref->{proargnames};
my @proc_args;
if ( !$ref->{proname} ) { # no such function
# If the function doesn't exist, $funcname gets zeroed?
$self->error( "No such function: $funcname");
# die;
}
$ref->{pronargs} = 0 unless defined $ref->{pronargs};
# If the user provided args..
if (!defined $args{args}) {
@proc_args = $self->_parse_array($pargs);
if (@proc_args) {
for my $arg (@proc_args) {
#print STDERR "User Provided Args: $arg\n";
if ( $arg =~ s/^in_// ) {
if ( defined $self->{$arg} )
{
$logger->debug("exec_method pushing $arg = $self->{$arg}");
}
else
{
$logger->debug("exec_method pushing \$arg defined $arg | \$self->{\$arg} is undefined");
#$self->{$arg} = undef; # Why was this being unset? --CT
}
push ( @call_args, $self->{$arg} );
}
}
}
for (@in_args) { push @call_args, $_ } ;
$self->{call_args} = \@call_args;
$logger->debug("exec_method: \$self = " . Data::Dumper::Dumper($self));
return $self->call_procedure( procname => $funcname,
args => \@call_args,
order_by => $self->{_order_method}->{"$funcname"},
schema=>$schema,
continue_on_error => $args{continue_on_error});
}
else {
return $self->call_procedure( procname => $funcname,
args => \@in_args,
order_by => $self->{_order_method}->{"$funcname"},
schema=>$schema,
continue_on_error => $args{continue_on_error});
}
}
Opportunities for Future Improvements
Initial improvements include replacing the enumerated argument API with one where a hashref can be passed overwriting part or all of the args sent to the database. This would continue to make the API flexible and dynamic but would allow for richer client code. The ordering API also needs to be moved into the actual API call, instead of a separate call.
Next Generation Interface Under Development
The next generation interface will support an API call like:
SELECT * FROM save('(,A-12334,"Test, Inc.",232)'::entity);
The major challenge here is recursively building what is essentially a potentially nested CSV structure. For example, we might have:
SELECT * FROM save('(,JE-12334,Cash Transfer,2013-05-01,f,"{""(,4,-1000)"",""(,7,1200)"",""(,12,200)""}")'::journal_entry);
The escaping is not actually too hard. The key challenges are actually questions of performance optimizations, such as making sure that we cache data structures properly and the like.
However in addition to that problem I would like to be able to define window functions on result sets over the API so that running balances can be added in the database (where they can be done most efficiently).
A fair bit of work has been done on this already.
Licensing
The code above is licensed under the GNU General Public License version 2 or at your option any later version. The code is not the cleanest code we have written on the subject but it is the code which is used by LedgerSMB in production.
If you would like BSD-licensed code to work with, which is also likely cleaner code, please see the PHP implementation that John Locke and myself have put together.
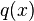 be a property provable about objects
be a property provable about objects  of type
of type  . Then
. Then 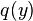 should be provable for objects
should be provable for objects  of type
of type  where
where